Writeup
Summary
PiMD is a SIMD intrinsics library for the Broadcom VideoCoreIV-AG100-R GPU found on all Raspberry Pi models. Currently there does not exist any general purpose libraries for the Raspberry Pi GPU. The goal of this library is to provide an accessible interface for taking advantage of the SIMD processors in the GPU, while providing performance comparable to application-specific QPU code. Our library is extremely versatile and can be used to implement nearly any purely data parallel algorithm.
Background
For more complete information about the Raspberry Pi's GPU, please see the VideoCore IV 3D Architecture Reference Guide.
QPU
At the core of VideoCore IV graphics processing unit is a set of 12 special purpose floating-point shader processors, termed Quad Processors (QPUs). Each QPU can be regarded as a 16-way 32-bit SIMD processor with an instruction cycle time of four system clocks. Our library only uses 8 of the QPUs in order to make it easier to evenly divide work among the QPUs (see VPM).
Registers
Each QPU contains four general-purpose accumulators as well as two large register-file memories, each with 64 registers. 32 locations on each of the A and B regfiles are general purpose registers while the other 32 are used to access register-space I/O. Our library uses the first 32 locations on each regfile to maintain user-defined variables during computation.
Uniforms
Uniforms are 32-bit values stored in memory that can be read in sequentially be the QPU. Our library uses uniforms to pass in function arguments, including memory address for general memory lookups (see TMU).
TMU
Each QPU has shared access to two Texture and Memory Lookup Unit (TMUs). The TMUs can be used for general memory lookups. Each TMU has a FIFO request queue, allowing the pipelining up of to four memory requests. Our library takes full advantage of this by aggressively prefetching data in order hide the latency of memory accesses.
VPM
The Vertex Pipeline Memory is a 4KB memory buffer shared among all the QPUs and intended for transferring data between the GPU and main memory. The QPUs views the VPM as a 2D array of 32-bit words, 16 words high and 64 words high. Our library partitions the VPM into 8 512 byte sections, allocating one to each QPU. Thus, each QPU is responsible for computing 8 16-wide 32-bit vectors at a time.
SFU
Each QPU has shared access to a Special Functions Unit (SFU) which can perform several less frequently used ‘exotic’ operations, including SQRT, RECIPSQRT, LOG, EXP. Our library provides access to these SFU functions.
Approach
Unlike Intel or Neon SIMD intrinsics, QPU code cannot be compiled alongside CPU code. QPU code is written in an assembly language specific to the QPU and compiled separately from any CPU code. In order to run code on the QPU, the compiled byte-code and all data must be structured in a specific way and passed in shared memory to the GPU. The primary goal of library was to abstract this complicated process away from the user and allow them to easily implement data parallel algorithms without having to worry about writing assembly, transferring data, or dividing work among the QPUs.
We worked to make a general interface that could be used with nearly any easily parallelization problem. We designed our library around a model of defining functions, consisting of QPU operations, and calling those functions on various inputs. This familiar model, used by nearly every higher-level programming language, makes our library extremely accessible, even to novice programmers.
Example code that implements SAXPY using the PiMD library:
#include <pimd.h>
int saxpy(int N, float scale, float X[], float Y[], result[]) {
# Open the mailbox interface to interact with the GPU.
int mb = pimd_open();
# Define the operations
PimdArg ops[] = {
OP_VLOAD, // Load a vector
OP_SFMUL, // Scale
OP_VFADD, // Second vector
OP_STORE // Result
};
# Create the function
PimdFunction function = PimdFunction(mb, ops, 4);
# Define the PiMD arguments
PimdArg args[] = {
&X, // Input vector
scale, // Scale
&Y, // Second vector
&result // Result
};
# Call the function
int ret = function.call(args, 4, N, 10000);
# Free the shared memory mapped by the function call
function.free();
# Close the mailbox interface
pimd_close(mb);
return ret;
}Abstraction
Our model abstracts away all notions of size related to the QPU execution. From the users perspective, operations are being applied to every element in their input array simultaneously. In our model, there is a single working vector to which all operations are applied. Arguments to operations on this working vector are fetched and loaded automatically by our library, which optimally prefetches values in order to hide memory latency. In addition there are 4 hardware variables that can be used to store and retrieve variables during computation. These variables are implemented as groups of registers, allowing users to use multiple variables without requiring more expensive memory requests.
Operations
Our library defines a set of operations that correspond to instructions on the QPU. Users create QPU functions by defining a series of these instructions. As you can see in the SAXPY example above, our function is defined as a vector load, a scalar float multiply, a vector float add, and a store. Each operation defines the input that it requires (for example, OP_ADD, OP_SADD, and OP_VADD take a variable, scalar, and vector argument respectively). This interface is simple, yet powerful by having function operations that map almost directly to hardware instructions.
Arguments
Arguments passed to PiMD functions must adhere to the specification implicitly defined by the series of operations that compose that function. In order to minimize boilerplate code needed to define arguments, the burden of ensuring that arguments are the correct type is passed along to the user. As a result, the same syntax is used to create arguments from integers, floats, and pointers, which can be seen in the SAXPY example above.
Results
Testing
In order to assess the performance of our library, we compared the performance of a variety of functions on the following implementations.
- CPU, single-threaded
- CPU NEON SIMD, single-threaded
- PiMD GPU library
We tested algorithms encompassing a variety of memory and computation profiles in order to see how our library performs what types of problems are well suited for execution on the QPU.
- Benchmarks
- Bandwidth-Bound: Repeatedly load and store every element in an input array to and from main memory. We used a large enough collection of memory addresses to ensure that values are not being cached. We tested this benchmark on inputs with 5M, 10M, 15M, and 20M elements.
- Compute-Bound: Repeatedly perform floating-point operations on an 1024 element array. We tested this benchmark on functions with 100K, 200K, 300K, and 400K operations.
- Algorithms
- SAXPY: Compute a * X + Y, where a is a scalar and X, Y are vectors. We tested SAXPY on inputs with 5M, 10M, 15M, and 20M elements.
- Image Processing
- Gaussian Blur: 2D convolution implementing a Gaussian blur. We tested this function on a variety of input images and the performance and results using our library were comparable to other Gaussian blur implementations.
Speedup
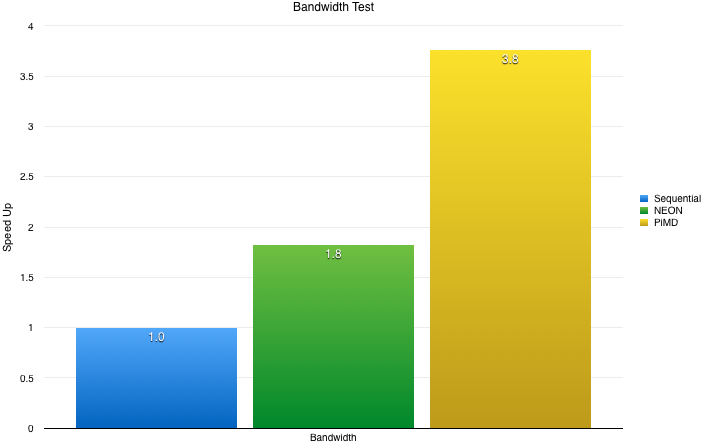
- Bandwidth-Bound
- NEON from Seq: 1.82x
- PiMD from Seq: 3.76x
- Pimd from NEON: 2.07x
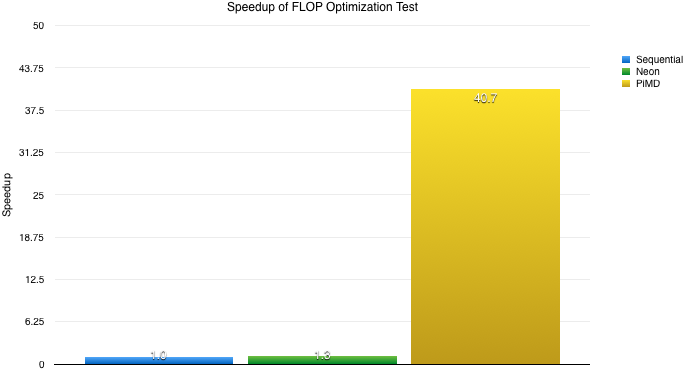
- Compute-Bound
- NEON from Seq: 1.25x
- PiMD from Seq: 40.66x
- Pimd from NEON: 32.53x
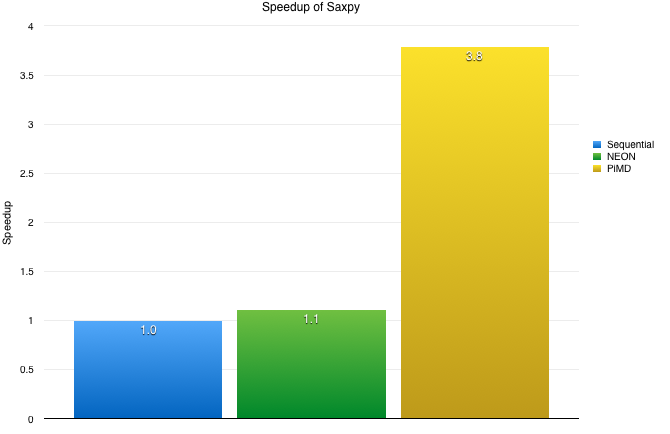
- SAXPY
- NEON from Seq: 1.11x
- PiMD from Seq: 3.79x
- Pimd from NEON: 3.41x
From the above graphs we can see that our library performed extremely well. It repeatedly out-performed both the CPU and NEON SIMD implementation on all varieties of tasks. Although these test may not be an entirely fair comparison because the CPU and NEON SIMD implementations were limited to one thread, they give us a good indiciation that the library is effective in speeding up data parallel computations.
We can also see that relative to the other implementations, our library performed the best on the compute bound test consisting of only floating-point operations. This suggests that the PiMD library is better suited for algorithms with high arithmetic intensities, as opposed to ones that require large memory transfers. This is unsurprising, as transferring data to and from memory is often a limiting factor in other GPUPU frameworks.
Conclusion
After implementing this library we learned quite a bit about the architecture and capabilities of the Broadcom VideoCoreIV-AG100-R GPU. Our major takeaways are:
- It is surprisingly powerful hardware when used effectively and efficiently. It is more than comparable with performance of the NEON SIMD on the ARM CPU.
- It is primarily limited by memory size. The latest Raspberry Pi models only have 1GB of main memory, which severly limits the size of input data, which has to be duplicated in memory to be used on the GPU. In addition, because the VPM memory buffer is only 4KB, QPU execution requries frequent memory transfers to store results.
- The Raspberry Pi GPU is an extremely good value, in terms of cost per FLOP, exceeding many supercomputers. However, the Raspberry Pi's hardware limitations make it impractical to exploit this for less expensive large scale computations.
Our PiMD library provides an accessible, flexible, and powerful interface for the Videocore GPU. The main benefits of our library are:
- It is enables developers to take advantage of the GPU without needing an in depth understanding of its architecture. Writing in QPU asssembly requries a sufficient understand of all the subtle rules and restrictions regarding various instructions and registers, as well as how to correctly use the I/O mapped registers.
- It exposes the full set of QPU arithmetic instructions, allowing users to define nearly any more complex functions by composing it of lower level operations.
- Our library has very low overhead by directly mapping arithmetic operations to their corresponding instruction. Furthermore, by efficiently scheduling memory fetches and memory stores, we achieve early nearly optimal memory performance.
Future Work
As mentioned previously, our comparison may be slightly unfair because they CPU and NEON SIMD implementations are single-threaded. It would be insightful to compare the performance of our library, which takes advantage of 8 QPUs, to multi-threaded CPU and NEON SIMD implementations that can take advantage of the Raspberry Pi's quad-core CPU.
Our results suggest that PiMD may also be well suited for image manipulations, which are often highly data parallel with high arithmetic intensity. Assessing the performance of our library on the following image manipulation algorithm could provide further useful data.
- RGB Manipulation: Single image tint, shade, color swap, and opacity filters.
- Blend Images: Blend multiple images according to given parameters for each channel.
- Edge Detection: Compute pixel differences implementing edge detection.
References
- VideoCore IV 3D Architecture Reference Guide - http://www.broadcom.com/docs/support/videocore/VideoCoreIV-AG100-R.pdf
- vc4asm Macroassembler for VideoCore IV - http://maazl.de/project/vc4asm/doc
- Raspberry Pi ARM side GPU libraries - https://github.com/raspberrypi/userland
- Videocore QPU Tutorial - https://github.com/hermanhermitage/videocoreiv-qpu